1、RabbitMQ 简说
MQ 版本:rabbitmq-3.13.0 & erlang-26.2.2
系统:Deepin V20 & Rocky Linux 9.3
什么是 MQ
消息(Message):在多个应用之间传递的数据。如文本字符串、JSON 等。
消息队列(Message Queue):一种跨进程传递消息的通信机制,用于上下游传递消息。
使用 MQ 的原因
MQ 具有 流量削峰、应用解耦、异步处理、广播、最终一致性 的能力。。
流量削峰:解决高并发问题
假设,正常情况下,订单系统可以处理 1W 个订单。突发情况,流量激增,出现了 2W 个订单,此时,系统难以处理。若使用 MQ 做缓冲层处理,可以把订单分散到 MQ 中处理。

应用解耦:提升系统可用性
假设电商系统中:订单系统、库存系统、物流系统、支付系统。用户下单支付时,任何一个系统出现故障,都会导致下单失败。使用 MQ 后,假设物流系统出现故障,物流系统需要处理的数据被缓存在了 MQ 中,不影响其他的系统的使用。物流系统恢复后,继续处理物流信息即可。

异步处理:提升响应速度
有些任务是耗时的,需要异步进行处理。如 A 调用 B,但 B 是一个耗时的任务,A 不知道 B 什么时候可以处理完成。按照以往的方法:A 每隔一段时间去调用 B,问它处理好了没有了;A 提供一个回调函数,当 B 处理完成后调用 A 的回调函数,通知 B 我已经处理完了。
使用 MQ 后可以很容易处理这个问题。 A 调用 B 后,只需要监听 B 处理完成的消息。当 B 处理完成后,发送一条消息给 MQ,MQ 会把消息转发给 A,这样 A 就知道 B 有没有处理完成。
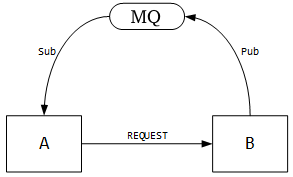
广播
没有消息队列时,当有新的业务接入时,都需要进行接口调试。使用 MQ 后,只需要关系消息是否送到了队列,至于是谁来订阅,MQ 不管。
最终一致性
最终一致性指的是两个系统的状态保持一致,要么都成功,要么都失败。理论上,当然是越快越好,保持数据一致性。但是实际情况中,会因各种情况导致数据无法实时保持一致性,但是最后两个系统的数据是一致的。
什么时候使用 MQ
既然 MQ 这么好,那我每个应用都使用它哪了。千万别这样,需要根据实际情况来确定。MQ 的引入,同时也增加了系统的复杂性。
一般情况下参考如下:
- 上游不关心下游执行结果
- 上游关心下游执行结果,但执行时间很长
- 数据库驱动的任务依赖。
那么什么时候不使用 MQ?当上游实时关注执行结果,就不需要使用 MQ 了,通常常用 RPC。
主流 MQ
| 特性 | RabbitMQ | RocketMQ | kafka |
|---|---|---|---|
| 开发语言 | erlang | java | scala |
| 支持协议 | AMQP,XMPP,SMTP,STOMP | 自定义 | 基于 TCP 自定义 |
| 客户端支持 | 支持 Erlang、PHP、Java、Ruby 等 | Java,C++ | Java、PHP、Python 等 |
| 消息存储能力 | 内衬、磁盘支。持少量堆积 | 磁盘。支持大量堆积 | 内存、磁盘、数据库。支持大量堆积 |
| 消息事务性 | 支持(信道设置事务模式,性能有影响) | 支持 | 支持 |
| 单机吞吐量 | 万级 | 10万级+ | 10万级+ |
| 时效性 | 微妙级 | 毫秒级 | 毫秒级以内 |
| 消息重复 | 支持at least once、at most once | 支持at least once | 支持at least once、at most once |
| 消息回溯 | 不支持 | 支持指定时间点的回溯 | 支持指定分区offset位置的回溯 |
| 消息重试 | 不支持,但可以设置autoACK=false,未收到确认的会重入队列 | 支持 | 不支持,但可以通过消息回溯的方式来实现 |
| 可用性 | 高(主从架构) | 非常高(分布式架构) | 非常高(分布式架构) |
| 功能特性 | 基于erlang开发,所以并发能力很强,性能极其好,延时很低 | MQ 功能比较完备,扩展性佳 | 只支持主要的 MQ 功能,在大数据领域应用广 |